Kubernetes 배포 시 502,504가 발생할 때
이슈 상황
Kubernetes에 새로운 Deployment를 apply 할 때 마다, LB에서 일부 502/504 응답이 보임
GitHub 이슈에도 아직 Open 상태 (무려 2020년에 Open된 이슈다!!!)
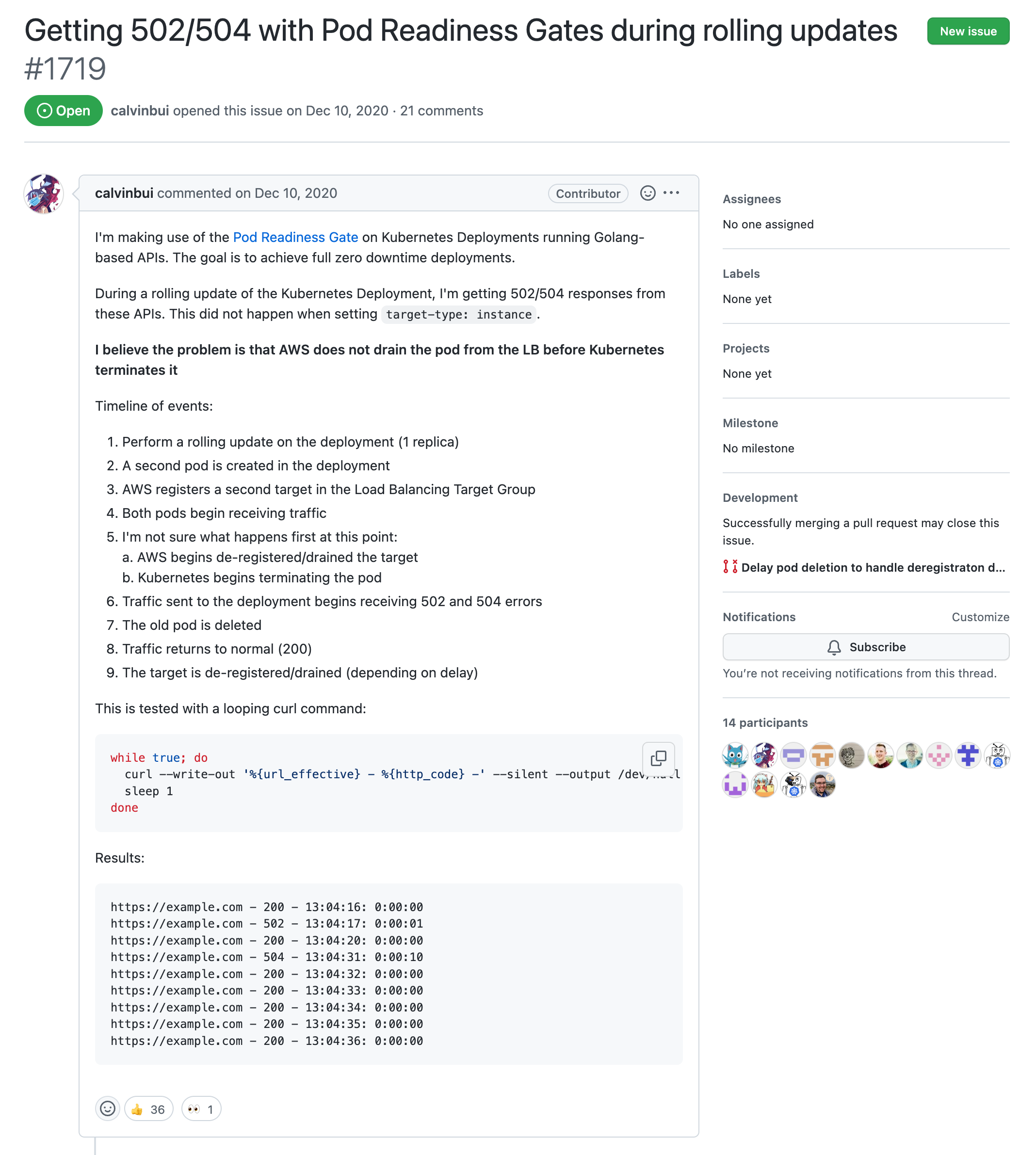
EntryPoint에서 signal을 처리하고 있지 않다면, 실행하는 어플리케이션(java spring, node-express 등등)으로 pass해주거나, signal을 처리하여야 함
Dockerfile
ENTRYPOINT ["exec", "실행하는 어플리케이션"] #exec를 사용하면 프로세스를 어플리케이션으로 대체하기 때문에, 어플리케이션으로 signal이 전달 됨
preStop에서 Sleep을 넣어줘야 함
Deployment.yaml
apiVersion: apps/v1
kind: Deployment
spec:
template:
spec:
containers:
- name: 이름
lifecycle:
preStop:
exec:
command:
- /bin/sleep
- "10"
1에서 Signal을 처리하여 어플리케이션이 Graceful shutdown 하는 시간, preStop에서 설정한 sleep 시간의 합보다 큰 값으로 Deployment의 terminationGracePeriodSeconds를 설정한다.
apiVersion: v1
kind: Pod
metadata:
name: pods-termination-grace-period-seconds
spec:
containers:
- command:
- sleep
- "3600"
image: busybox
name: pods-termination-grace-period-seconds
terminationGracePeriodSeconds: 5
preStop의 sleep이 먼저 동작하고, 이후 SIGTERM을 수신하여 pod의 graceful shutdown 로직이 동작하고, 만약 이 시간이 terminationGracePeriodSeconds을 초과한다면 약 2초 정도 뒤에 SIGKILL이 Pod로 보내진다.
그러니 terminationGracePeriodSeconds 안에 shutdown이 이뤄질 수 있도록 적절한 시간을 설정하자.
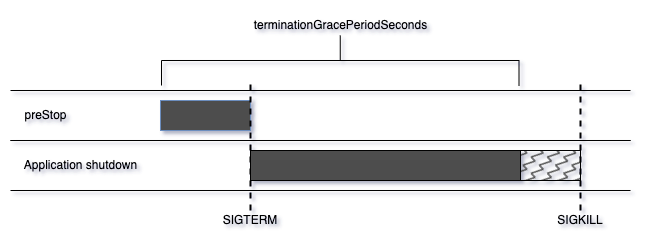
Kubernetes가 terminating 중인 pod에 여전히 트래픽을 라우팅하기 때문이다.
Kubernetes에서 pod가 종료될 때, 다음 2가지 명령이 asynchronous하게 수행된다.
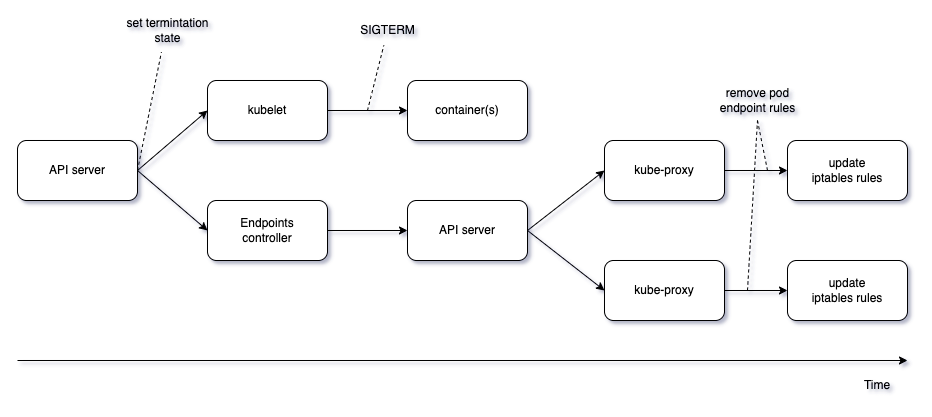
Pod로의 라우팅 삭제까지 pod 종료보다 더 많은 단계를 거쳐야 하니, pod 종료보다 더 오래 걸릴 확률이 높고, terminating 상태로 바뀐 pod로 트래픽을 보낼 확률이 높다는 것이다.
그래서 prestop에 sleep을 충분한 시간(10초) 동안 줘서, kube-proxy의 iptables rule이 업데이트 되고 난 후 pod를 종료 시킬려고 하는 것이다.
근데 sleep 말곤 다른 방법이 없는 것인가?

쿠버네티스에서 kube-proxy의 iptables rule에서 해당 pod가 제거 되었다는 것이 보장되었을 때 kubelet이 해당 pod에 SIGTERM을 보내주도록 해야할 것인데, 아직도 관련 소식이 없는걸 보면 고칠 생각이 없는 것 같기도 하다.
sleep을 쓰고 싶지 않다면 어플리케이션에서 SIGTERM을 수신했을 때, 타이머를 두고 특정 타이머 시간 동안 새로운 요청이 들어오지 않는다면 그때서야 종료하는 방법으로 구현해볼 수 있을 것이다.
Pod로의 라우팅룰이 kube-proxy의 iptables에서 빠지기 전에 새로운 트래픽이 해당 Pod로 가는 것이 문제이기 때문에, 위의 방법으로도 해결해볼 수도 있겠으나, 쿠버네티스의 문제를 해결하기 위해 어플리케이션 로직을 복잡하게 가져가는 것이 맞는가라는 생각도 든다.
그리고 preStop도 위의 이슈를 해결하기 위해 설계된 spec이 아니다. 만약 추후에 이 문제가 해결된다면 preStop에 sleep을 통해 해결한 방법을 다시 고려해봐야할 수도 있다.
OpenLens 6.3.0부터 Pod attach나 Log 버튼이 보이지 않는다.
Github과 Jekyll을 사용하여 Blog를 개설했다.